
TV Audience Viewing Data Worldwide – FOCUS ON HOLLAND
One of the best examples of TV audience viewing data worldwide comes from Holland, in the shape of Nationaal Media Onderzoek (NMO).
Under the banner of NMO, the reach of television, radio, print and online is measured. The National Media Research (NMO) is an initiative of the media reach research organisations in the Netherlands. NMO is a merger of the following: Stichting KijkOnderzoek (SKO), Stichting Nationaal Luister Onderzoek (NLO), Stichting Nationaal Onderzoek Multimedia (NOM), In 2024, Stichting Buitenreclame Onderzoek (BRO) and the United Internet Operators (VINEX).
The NMO data portal at this link provides comprehensive audience viewing data. Users can choose daily, monthly or annual data before filtering and downloading. Data can be chosen by various channel, programme and audience number parameters.

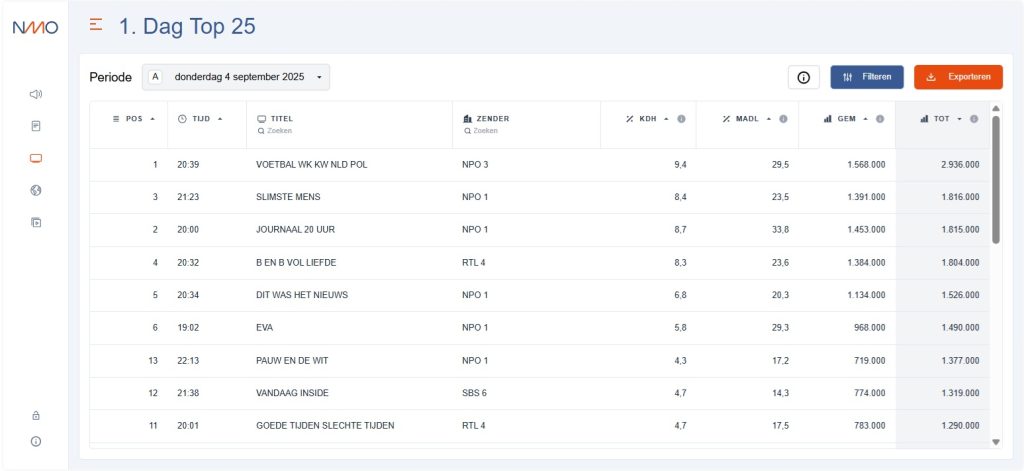
A small part of the system is in English with the majority naturally being in Dutch.
To assist you in translating the meaning of some of the data headings a short glossary in provided below.
KDH = The percentage of the Dutch population aged 6 years and older who have watched the programme or channel on average (viewing density in %).
MADL = The percentage of viewers to the program or channel, as a share of the total number of TV viewers at that time.
GEM = Average number of viewers; the average number of people within the Dutch population aged 6 years and older who have watched the programme or channel (viewing density in absolute numbers).
UNTIL = Total viewers; the number of people within the Dutch population aged 6 years and older who watched the programme for at least 1 consecutive minute (range in absolute numbers).
NMO also publish the results of studies in pdf download format. The sample below shows that Holland like other countries is facing a sharp decline in linear TV viewing.
IN ADDITION TO AUTONOMOUS DECLINE, PANEL UPDATE NMO KIJKONDERZOEK (TAM) ALSO LEADS TO A DECLINE IN LINEAR VIEWING TIME
For the past six months, the updated NMO Kijkonderzoek (The Dutch TAM) has been providing the common currency for the television market. The NMO Kijkonderzoek, like other sources, shows an
autonomous declining trend in linear viewing time. The decline appears to be larger in certain target groups than in the overall 6+ group, especially among the 35 to 49-year-olds and the 20 to 49-yearolds. This becomes especially visible after the planned panel update that was carried out just before the launch of the new audience measurement.
Last month, NMO carried out a comprehensive benchmark analysis. This was prompted by the sharp drop in viewing time. In all other data sources that were compared with the NMO Kijkonderzoek, the
same picture is consistently visible: an autonomous declining trend in linear viewing time can be found everywhere.
The Netherlands is not unique in this respect. However, as a result of the planned panel update, the decrease in certain target groups appears to be relatively large. In a panel update, the background characteristics of all panel members are refreshed. For example, the age of all panel members increases by one year. This adjustment takes place once a year, for all panel members simultaneously. The effect is that younger panellists with less viewing time are added to certain target groups and older panellists with more viewing time leave the target group. Thus, in the case of the 35 to 49-year-olds, 34-year-olds enter and 49-year-olds leave. Because the younger entrants have a lower viewing time, this results in a decrease in viewing time in some target groups.